Further information
Chapter 1: Precognition studies and the curse of the failed replications
The following is an article from The Guardian in which Chris French discusses the system of peer review that allowed a prestigious journal to refuse to publish a failed replication of some otherwise astonishing pre-cognition (predicting the future) studies.
http://www.theguardian.com/science/2012/mar/15/precognition-studies-curse-failed-replications
Chris French is a professor of psychology at Goldsmiths, University of London, and heads the Anomalistic Psychology Research Unit. He edits The Skeptic magazine.
An extended discussion of the concept of ecological validity
In Chapter 4 there is a discussion of the much misused and poorly understood concept of ecological validity. This is the original discussion which I trimmed down for the book.
Ecological validity
In this edition I decided to fully discuss the meaning of this enigmatic and catch-all term ‘ecological validity’ because its widespread and over-generalised use has become somewhat pointless. Hammond (1998) refers to its use as ‘casual’ and ‘corrupted’ and refers to the robbing of its meaning (away from those who continue to use its original sense) as ‘bad science, bad scholarship and bad manners’.
There are three relatively distinct and well used uses of the term, which I shall call ‘the original technical’, ‘the external validity version’ and ‘the pop version’, the latter term to signify that this use I would consider to be unsustainable since it has little to do with validity and its indiscriminate use will not survive close scrutiny.
1. The original technical meaning
Brunswik (e.g., 1947) introduced the term ecological validity to psychology as an aspect of his work in perception ‘to indicate the degree of correlation between a proximal (e.g., retinal) cue and the distal (e.g., object) variable to which it is related’ (Hammond, 1998). This is a very technical use. The proximal stimulus is the information received directly by the senses – for instance two lines of differing lengths on our retinas. The distal stimulus is the nature of that actual object in the environment that we are receiving information from. If we know that the two lines are from two telegraph poles at different distances from us we might interpret the two poles as the same size but one further away than the other. The two lines have ecological validity in so far as we know how to usefully interpret them in an environment that we have learned to interpret in terms of perspective cues. The two lines do not appear to us as having different lengths because we interpret them in the context of other cues that tell us how far away the two poles are. In that context their ecological validity is high in predicting that we are seeing telegraph poles. More crudely, brown patches on an apple are ecologically valuable predictors of rottenness; a blue trade label on the apple tells us very little about rot.
2. The external validity meaning
Many textbooks, including this one, have taken the position that ecological validity is an aspect of external validity and refers to the degree of generalisation that is possible from results in one specific study setting to other different settings. This has usually had an undertone of comparing the paucity of the experimental environment with the greater complexity of a ‘real’ setting outside the laboratory. In other words researchers asked ‘how far will the results of this laboratory experiment generalise to life outside it?’ The general definition, however, has concerned the extent of generalisation of findings from one setting to another and has allowed for the possibility that a study in a ‘real life’ setting may produce low ecological validity because its results do not generalise to any other setting – see the Hofling study below. Most texts refer to Bracht and Glass (1968) as the originators of this sense of the term and the seminal work by Cook and Campbell (1979) also supported this interpretation.
On this view effects can be said to have demonstrated ecological validity the more they generalise to different settings and this can be established empirically by replicating studies in different research contexts.
3. The ‘pop’ version
The pop version is the definition very often taught on basic psychology courses. It takes the view that a study has (high) ecological validity so long as the setting in which it is conducted is ‘realistic’, or the materials used are ‘realistic’, or indeed if the study itself is naturalistic or in a ‘natural’ setting (e.g., Howitt, 2013). The idea is that we are likely to find out more about ‘real life’ if the study is in some way close to ‘real life’, begging the question of whether the laboratory is not ‘real life’.
The problem with the pop version is that it has become a knee-jerk mantra – the more realistic the more ecological validity. There is, however, no way to gauge the extent of this validity. It is just assumed, so much so that even A-level students are asked to judge the degree of ecological validity of fictitious studies with no information given about successful replications or otherwise.
Teaching students that ecological validity refers to the realism of studies or their materials simply adds a new ‘floating term’ to the psychological glossary that is completely unnecessary since we already have the terminology. The word to use is ‘realism’. As it is, students taught the pop version simply have to learn to substitute ‘realism’ when they see ‘ecological validity’ in an examination question.
For those concerned about the realism of experimental designs Hammond (1998) points out that Brunswick (1947) introduced another perfectly suitable term. He used representative design to refer to the need to design experiments so that they sample materials from among those to which the experimenter wants to generalise effects. He asked that experimenters specify in their design the circumstances to which they wished to generalise. For instance, in a study on person perception, in the same way as we try to use a representative sample of participants, we should sample a representative sample of stimulus persons (those whom participants will be asked to make a judgment about) in order to be able to generalise effects to a wider set of perceived people. Hammond is not the only psychologist worried about the misuse of Brunswik’s term. Araújo, Davids and Passos (2007) argue that the popular ‘realism’ definition of ecological validity is a confusion of the term with representative design:
‘… ecological validity, as Brunswik (1956) conceived it, refers to the validity of a cue (i.e., perceptual variable) in predicting a criterion state of the environment. Like other psychologists in the past, Rogers et al. (2005) confused this term with another of Brunswik’s terms: representative design.’ (p.69)
This article by Araújo et al is a good place to start understanding what Brunswik actually meant by ecological validity and demonstrates that arguments to haul its meaning back to the original are contemporary and not old-fashioned. The term is in regular use in its original meaning by many cognitive psychologists. They are not clinging to a ‘dinosaur’ interpretation in the face of unstoppable changes in the evolution of human language.
Milgram v. Hofling – which is more ‘ecologically valid’?
Another problem with the pop version is that it doesn’t teach students anything at all about validity as a general concept. It simply teaches them to spot when material or settings are not realistic and encourages them to claim that this is a ‘bad thing’. It leads to confusion with the laboratory–field distinction and a clichéd positive evaluation of the latter over the former. For example, let’s compare Milgram’s famous laboratory studies of obedience with another obedience study by Hoflinget al (1966), where nurses working in a hospital, unaware of any experimental procedure, were telephoned by an unknown doctor and broke several hospital regulations by starting to administer, at the doctor’s request, a potentially lethal dose of an unknown medicine. The pop version would describe Hofling’s study as more ‘ecologically valid’ because it was carried out in a naturalistic hospital setting on real nurses at work. In fact, this would be quite wrong in terms of external validity since the effect has never been replicated. The finding seems to have been limited to that hospital at that time with those staff members. A partial replication of Hofling’s procedures failed to produce the original obedience effect (Rank and Jacobson, 19771), whereas Milgram’s study has been successfully replicated in several different countries using a variety of settings and materials. In one of Milgram’s variations, validity was demonstrated when it was shown that shifting the entire experiment away from the university laboratory and into a ‘seedy’ downtown office, apparently run by independent commercial researchers, did not significantly reduce obedience levels. Here, following the pop version, we seem to be in the ludicrous situation of saying that Hofling’s effect is valid even though there is absolutely no replication of it, while Milgram’s is not, simply because he used a laboratory! In fact Milgram’s study does demonstrate ecological validity on the generalisation criterion. The real problem is that there is no sense of ‘validity’ in the pop notion of ecological validity.
In a thorough discussion of ecological validity Kvavilashvili and Ellis (2004) bring the original and external validity usages together by arguing that both representativeness and generalisation are involved, with generalisation appearing to be the more dominant concept. Generalisation improves the more that representativeness is dealt with. However, they argue that a highly artificial and unrealistic experiment can still demonstrate an ecologically valid effect. They cite as an example Ebbinghaus’s memory tasks with nonsense syllables. His materials and task were quite unlike everyday memory tasks but the effects Ebbinghaus demonstrated could be shown to operate in everyday life, though they were confounded by many other factors. The same is true of research in medicine or biology; we observe a phenomenon, make highly artificial experiments in the laboratory (e.g., by growing cultures on a dish) then re-interpret results in the everyday world by extending our overall knowledge of the operation of diseases and producing new treatments. In psychology, though, it is felt that by making tasks and settings more realistic we have a good chance of increasing ecological validity. Nevertheless, ecological validity must always be assessed using research outcomes and not guessed at because a study is ‘natural’.
I think the conclusions that emerge from this review of the uses of ecological validity are that:
- Examiners (public or institutional) should certainly not assess the term unless they are prepared to state and justify explicitly the specific use they have in mind prior to any examinations.
- The pop version tells us nothing about formal validity and is a conceptual dead end; ‘realism’ can be used instead and ‘ecological validity’ takes us no further.
- Rather than ‘ecological validity’ it might be more accurate to use the term ‘external validity concerning settings’. Although in 1979 Cook and Campbell identified ecological validity with generalisation to other settings (i.e., external validity), in their update of their 1979 classic, Shadish, Cook and Campbell (2002) talk of external validity with regard to settings. They seem to pass the original term back to Brunswik saying that external validity is often ‘confused with’ ecological validity. By contrast, Kvavilashvili and Ellis (2004) argue that ‘the difference between the two concepts is really small’. Obviously we cannot hope for pure agreement among academics!
- It is ridiculous to assume that on the sole basis that a study is carried out in a natural setting or with realistic materials it must be in some way more valid than a laboratory study using more ‘artificial’ materials. Validity is about whether the effect demonstrated is genuinely causal and universal. An effect apparently demonstrated in the field can easily be non-genuine and/or extremely limited, as was Hofling’s.
- The pop version cannot be sustained scientifically and is not of much use beyond being a technical sounding substitute for the term ‘realism’. The original version is still used correctly by those working in perception and related fields. The external validity (generalising) version is favoured by Kvavilashvili (over representativeness), and directs attention to a useful aspect of validity in the design of research. However, the external validity version is challenged by authors such as Hammond (1998) and Araújo et al (2007), who claim that this is not at all what Brunswik meant nor is it the way cognitive psychologists use the term. Perhaps it’s better to lie low, use alternative terminology, and see how the term evolves. I rather sense that the pop version will hang around, as will complete misunderstanding of the terms ‘null hypothesis’ and ‘negative reinforcement’.
1. Unlike in Hofling’s study, nurses were familiar with the drug and were able to communicate freely with peers.
Festinger's end-of-the-world study 'Under Cover'
In a famous participant observation case study, Leon Festinger, Henry W. Reiken and Stanley Schachter (1956) studied a woman they called Mrs Keech who had predicted the end of the world by a mighty flood. After reading about Mrs Keech in a newspaper, Festinger’s group joined her followers to see what would happen when the world did not, in fact, come to an end.
Mrs Keech claimed to have been receiving messages from a group called the Omnipotent Guardians from the planet Clarion. They had sent her messages through a combination of telepathy, automatic writing and crystal ball gazing to indicate that at midnight on a particular December evening the world would be destroyed, killing all humanity except for Mrs Keech’s group. They were to be rescued by flying saucers sent from Clarion to Mrs Keech’s home. During the weeks before the ‘end of the world’, several of the group members quit their jobs and spent their savings in preparation for the end. Messages continued to arrive daily to Mrs Keech. At meetings Festinger and his associates frequently would excuse themselves and write down their notes while in the bathroom. At one meeting, the members were asked to look into a crystal ball and report any new pieces of information. One member of Festinger’s group was forced to participate, even though he was hesitant to take a vocal role in meetings. After he remained silent for a time, Mrs Keech demanded that he report what he saw. Choosing a single word response, he truthfully announced, ‘Nothing’. Mrs Keech reacted theatrically, ‘That’s not nothing. That’s the void.’
On the final evening, members of the group waited for midnight. During the evening other instructions arrived. Cultists were told to remove their shoelaces and belt buckles since these items were unsafe aboard flying saucers. When midnight passed without any end of the world in sight – and without any flying saucers visible – members of the group began questioning whether they had misunderstood the instructions. Mrs Keech began to cry and whimpered that none of the group believed in her. A few of the group comforted her and reasserted their belief in her. Some members re-read past messages, and many others sat silently with stony expressions on their faces. Finally, in the wee hours of the morning, Mrs Keech returned to the group with a new ‘automatically written’ message from the Omnipotent Guardians. Because of the faith of the group, the Earth had been spared. The cult members were exuberant and during the weeks that followed actually attempted to secure additional converts.
One can find both insight and some entertainment in such a participant observation study. To Festinger’s group of scholars, the experience permitted them to provide a field study examination (in the form of a case study) of the theory of cognitive dissonance that they were trying to develop at the time – a theory that became a major force in communication and social psychology.
Excerpted from John C. Reinard, Introduction to Communication Research. Boston, McGraw-Hill, 2001, pp 186–8.
Analysing qualitative data
The Jefferson transcription system
Chapter 12 of the book promises to provide some details of the Jefferson transcription system, used to transcribe recorded conversations into text. Here they are. First of all though a few points about the system.
1. The system is used thoroughly in conversation analysis (see Hutchby and Wooffitt, 1998 – reference is in the book). In this approach there are two major concerns – those of turn-taking and of the characteristics of speech delivery. As you can see from the symbols below, many of these concern how a speech partner overlaps or take over from another (e.g., simply the fact of transcription line numbers) and how speech is presented (emphasis, rising tone, pauses and so on). As an exercise listen to a conversation and observe how people use pauses in order to ‘keep the floor, i.e., indicate that they want to go on speaking and not be interrupted. In some Australian and Californian accents there is a marked up turn at the end of an utterance when the speaker indicates the end of their speech and invites a reply.
2. The most important point is that the system is intricate and time hogging so check first that you really do need to use it! Most grounded theory approaches would not transcribe in this kind of detail. The system is used mainly in conversation analysis where researchers are interested in the analysis of para-linguistics, in a nutshell, not what is said but how it is said, for instance, emphasis, rising and falling tones, hesitations, etc. Such hesitation might indicate, for instance, that the speaker is embarrassed or in some way has a problem with what they are saying. You can of course indicate that there was such hesitation without resorting to the details of Jefferson.
3. Any two transcribers will come up with slightly different transcriptions. There is no clear criterion as to what counts as a marked or ‘less marked’ fall in pitch, for instance.
4. Each new utterance (according to the researcher’s hearing) is given a new line number in the transcript.
5. You would need a recording system that permits you to constantly rewind very short sections of speech. Researchers have traditionally used transcription machines although computer programmes can now do the job quite well.
John: |
Used on the left hand side of the transcript indicates the speaker. |
?: |
Indicates the speaker is unknown to the transcriber; ?John: indicates a guess that the speaker is John. |
|
|
(0.5) |
Indicates a time interval in seconds. |
(.) |
Indicates a pause of less than 0.2 seconds. |
= |
‘Latching’ – the point where one person’s speech ends and continues on a new line without pause, usually after a fragment from their conversation partner, e.g., |
[ ] |
Brackets used where there is overlapping talk as in the example above where speaker B overlaps speaker A. |
hh |
Speaker breathes out – more hs means a longer breath. |
.hh |
Speaker breathes in – more hs, longer intake of breath. |
(( )) |
Double brackets can be used to describe a non-verbal sound (such as a kettle boiling) or something else in the context which the transcriber would like to convey (e.g., that a person is frowning whilst speaking). |
- |
Indicates the last word was suddenly cut off as in the example above, first line. |
: |
The previous sound has been stretched; more colons greater stretching, as in thee example above after ‘Sun’. |
! |
Indicates emphasis – energised speech. |
( ) |
The passage of speech is unclear. The distance between indicates the estimated length of the piece. If there is speech between the brackets it is the transcriber’s best ‘guess’ at the speech. |
. |
fall in tone indicating a stop |
, |
‘continuing’ intonation |
? |
Rising inflection, as in but not exclusively so, a question. |
¯ |
Indicate marked rising or falling of tone – placed before the rise/fall. |
a: |
Less marked fall in pitch as in – B: ‘whaddya gonna do: there |
a: |
Less marked rise in pitch (underlined colon). |
Underline |
Emphasis on the underlined section. |
SHOUT |
Indicates the word in capitals was louder than those around it. |
° ° |
Speech between is noticeably softer than surrounding speech. |
> < |
Speech between is quicker than the rest. |
< > |
Speech between is slowed down. |
Largely based on Hutchby and Woffitt (1998) p. vi
A few of the symbols can be seen in this conversation sequence.
1 A: gmornin:. j’sleep OK
2 B: huh
3 A: was that a yes
4 B: hhh° yer °
5 A: HALL¯O:: (0.5) are we awake.
6 B: <just about>
7 A: >look we really need to talk [about the holiday<
8 B: [I know (.) the holiday
If you’d like to get practice specifically with conversation analysis or at least with this kind of transcription you could visit Charles Antaki’s Conversation Analysis website at:
http://homepages.lboro.ac.uk/~ssca1/sitemenu.htm
Where you can go through a script and look at various stages of transcription ending with a version using the notation system above.
Sod's Law – or Murphy’s law as the Americans more delicately put it
A discussion of Sod’s law – a BBC spoof documentary about testing the notion that toast always falls butter side down and other issues.
Do you ever get the feeling that fate has it in for you? At the supermarket, for instance, do you always pick the wrong queue, the one looking shorter but which contains someone with 5 un-priced items and several redemption coupons or with the checkout clerk about to take a tea break? Do you take the outside lane only to find there’s a hidden right-turner? Sod’s law (known as Murphy’s law in the US), in its simplest form states that whatever can go wrong, will. Have you ever returned an item to a shop, or taken a car to the garage with a problem, only to find it working perfectly for the assistant? This is Sod’s law working in reverse but still against you. A colleague of mine holds the extension of Sod’s law that things will go wrong even if they can’t. An amusing QED (BBC) TV programme (Murphy’s Law, 19911) tested this perspective of subjective probability. The particular hypothesis, following from the law, was that celebrated kitchen occurrence where toast always falls butter side down – doesn’t it? First attempts engaged a university physics professor in developing machines for tossing the toast without bias. These included modified toasters and an electric typewriter. Results from this were not encouraging. The null hypothesis doggedly retained itself, buttered sides not making significantly more contact with the floor than unbuttered sides. It was decided that the human element was missing. Sod’s law might only work for human toast droppers.
The attempt at more naturalistic simulation was made using students and a stately home now belonging to the University of Newcastle. Benches and tables were laid out in the grounds and dozens of students asked to butter one side of bread then throw it in a specially trained fashion to avoid toss bias. In a cunning variation of the experiment, a new independent variable was introduced. Students were asked to pull out their slice of bread and, just before they were about to butter a side, to change their decision and butter the other side instead. This should produce a bias away from butter on grass if sides to fall on the floor are decided by fate early on in the buttering process. Sadly neither this nor the first experiment produced verification of Sod’s law. In both cases 148 slices fell one way and 152 the other – first in favour of Murphy’s law then against it. Now the scientists had one of those flashes of creative insight. A corollary of Sod’s law is that when things go wrong (as they surely will – general rule) they will go wrong in the worst possible manner. The researchers now placed expensive carpet over the lawn. Surely this would tempt fate into a reaction? Do things fall butter side down more often on the living room carpet (I’m sure they do!)? I’m afraid this was the extent of the research. Frequencies were yet again at chance level, 146 buttered side down, 154 up.
Murphy, it turned out, was a United States services officer testing for space flight by sending service men on a horizontally jet propelled chair across a mid-Western desert to produce many Gs of gravitational pressure. I’m still not convinced about his law. Psychologists suggest the explanation might lie in selective memory – we tend to remember the annoying incidents and ignore all the un-notable dry sides down or whizzes through the supermarket tills. But I still see looks on customers’ faces as they wait patiently – they seem to know something about my queue …
1 Sadly no longer available except via The British Film Institute
The sociologist’s chip shop
An attempt to exemplify the concepts of the null hypothesis and significance in an everyday homely tale of chips.
Imagine one lunchtime you visit the local fish and chip emporium near the college and get into conversation with the chippy. At one point she asks you: ‘You’re from the college then? What do you study?’. Upon your reply she makes a rasping sound in her throat and snaps back. ‘Psychology?!!! Yeughhh!!! All that individualist, positivistic crap, unethical manipulation of human beings, nonsensical reductionism rendering continuous human action into pseudo-scientific behavioural elements. What a load of old cobblers! Give me sociology any day. Post-Marxist-Leninist socialism, symbolic interactionism, real life qualitative participative research and a good dollop of post-modern deconstructionism’. You begin to suspect she may not be entirely fond of psychology as an academic subject. You meekly take your bag of chips and proceed outside only to find that your bag contains far too many short chips, whilst your sociology friends all have healthy long ones.
We must at this point stretch fantasy a little further by assuming that this story is set in an age where, post-salmonella, BSE and genetically modified food, short chips are the latest health scare; long chips are seen as far healthier since they contain less fat overall (thanks to my students for this idea).
Being a well-trained, empirically based psychology student, you decide to design a test of the general theory that the chippy is biased in serving chips to psychology and sociology students. You engage the help of a pair of identical twins and send them simultaneously, identically clothed, into the chip shop to purchase a single bag of chips. One twin wears a large badge saying ‘I like psychology’ whilst the other twin wears an identical badge, apart from the replacement of ‘psychology’ with ‘sociology’. (OK! OK! I spotted the problem too! Which twin should go first? Those bothered about this can devise some sort of counterbalanced design – see Chapter 3 – but for now I really don’t want to distract from the point of this example). Just as you had suspected, without a word being spoken by the twins beyond their simple request, the sociology twin has far longer chips in her bag than does the psychology twin!
Now, we only have the two samples of chips to work with. We cannot see what goes on behind the chippy’s stainless steel counter. We have to entertain two possibilities. Either the chippy drew the two samples (fairly) from one big chip bin (H0) or the bags were filled from two separate chip bins, one with smaller chips overall and therefore with a smaller mean chip length than the other bin (H1). You now need to do some calculations to estimate the probability of getting such a large difference between samples if the bags were filled from the same bin (i.e., if the null hypothesis is true). If the probability is very low you might march back into the shop and demand redress (hence you have rejected H0!). If the probability is quite high – two bags from the same bin are often this different – you do not have a case. You must retain the null hypothesis.
In this example, our research prediction would be that the sociology student will receive longer chips than the psychology student. Our alternative hypothesis is that the psychology and sociology chip population means are different; the null hypothesis that the population means are the same (i.e., the samples were drawn from the same population).
Please, sir, may we use a one-tailed test, sir?
A discussion of the arguments for and against the use of one-tailed tests in statistical analysis in psychology.
It is hard to imagine statisticians having a heated and passionate debate about their subject matter. However, they’re scientists and of course they do. Odd, though, are the sorts of things they fall out over. Whether it is legitimate to do one-tailed tests in psychology on directional hypotheses is, believe it or not, one of these issues. Here are some views against the use of one-tailed tests on two-group psychological data.
A directional test requires that no rationale at all should exist for any systematic difference in the opposite direction, so there are very few situations indeed where a directional test is appropriate with psychological data consisting of two sets of scores.
MacRae, 1995
I recommend using a non-directional test to compare any two groups of scores … Questions about directional tests should never be asked in A level examinations.
MacRae, 1995
I say always do two-tailed tests and if you are worried about b, jack the sample size up a bit to offset the loss in power.
Bradley, 1983 (Cited in Howell, 1992)
And some arguments for the use of one-tailed tests are as follows:
To generate a theory about how the world works that implies an expected direction of an effect, but then to hedge one’s bet by putting some (up to 1⁄2) of the rejection region in the tail other than that predicted by the theory, strikes me as both scientifically dumb and slightly unethical … Theory generation and theory testing are much closer to the proper goal of science than truth searching, and running one-tailed tests is quite consistent with those goals.
Rodgers, 1986 (cited in Howell, 1992)
… it has been argued that there are few, if any, instances where the direction [of differences] is not of interest. At any rate, it is the opinion of this writer that directional tests should be used more frequently.
Ferguson and Takane, 1989
MacRae is saying that when we conduct a one-tailed test, any result in the non-predicted direction would have to be seen as a chance outcome since the null hypothesis for directional tests covers all that the alternative hypothesis does not. If the alternative hypothesis says the population mean is larger than 40 (say) then the null hypothesis is that the population mean is 40 or less. To justify use of a one-tailed test, you must, in a sense, be honestly and entirely uninterested in an effect in the opposite direction. A textbook example (one taken from a pure statistics book, not a statistics-for-social-science textbook) would be where a government agency is checking on a company to see that it meets its claim to include a minimum amount of (costly) vitamin X in its product. It predicts and tests for variations below the minimum. Variations above are not of interest and almost certainly are relatively small and rare, given the industry’s economic interests. A possibly equivalent psychological example could be where a therapist deals with severely depressed patients who score very much up the top end of a depression scale. As a result of therapy a decline in depression is predicted. Variations towards greater depression are almost meaningless since, after a measurement of serious depression, the idea of becoming even more depressed is unmeasurable and perhaps unobservable.
Rodgers, however, says what most people feel when they conduct psychological projects. Why on earth should I check the other way when the theory and past research so clearly point in this one direction? In a sense, all MacRae and Bradley are asking is that we operate with greater surety and always use the 2.5% level rather than the 5% level. If we’ve predicted a result, from closely argued theory, that goes in one direction, then use two-tailed values and find we are significant in the opposite direction, we’re hardly likely to jump about saying ‘Eureka! It’s not what I wanted but it’s significant!’ Probably we will still walk away glumly, as for a failure to reach significance, saying ‘What went wrong then?’ It will still feel like ‘failure’. If we had a point to make we haven’t made it, so we’re hardly likely to rush off to publish now. Our theoretical argument, producing our hypothesis, would look silly (though it may be possible to attempt an explanation of the unexpected result).
During this argument it always strikes me as bizarre that textbooks talk as if researchers really do stick rigidly to a hypothesis testing order: think through theory, make a specific prediction, set alpha, decide on one- or two-tailed test, find out what the probability is, make significance decision. The real order of events is a whole lot more disjointed than that. During research, many results are inspected and jiggled with. Participants are added to increase N. Some results are simply discarded.
Researchers usually know what all the probability values are, however, before they come to tackle the niggling problem of whether it would be advisable to offer a one- or two-tailed analysis in their proposed research article. When the one-tailed test decision is made is a rather arbitrary matter. In some circles and at some times it depends on the received view of what is correct. In others it depends on the actual theory (as it should) and in others it will depend on who, specifically, is on the panel reviewing submitted articles.
So what would happen, realistically speaking, if a researcher or research team obtained an opposite but highly ‘significant’ result, having made a directional prediction? In reality I’m sure that if such a reversal did in fact occur, the research team would sit back and say ‘Hmm! That’s interesting!’ They’re not likely to walk away from such an apparently strong effect, even though it initially contradicts their theorising. The early research on social facilitation was littered with results that went first one way (audiences make you perform better) then the other (no, they don’t; they make performance worse). Theories and research findings rarely follow the pure and simple ideal. It is rare in psychology for a researcher to find one contrary result and say ‘Oh well. That blows my whole theory apart. Back to the drawing board. What shall I turn my hand to today then?’ The result would slot into a whole range of findings and a research team with this dilemma might start to re-assess their method, look at possible confounding variables in their design and even consider some re-organisation of their theory in order to incorporate the effect.
It is important to recognise the usefulness of this kind of result. Far from leaving the opposite direction result as a ‘chance event’, the greater likelihood is that this finding will be investigated further. A replication of the effect, using a large enough sample to get p ≤ .01, would be of enormous interest if it clearly contradicts theoretical predictions – see what the book says about the 1% level.
So should you do one-tailed tests? This is clearly not a question I’m going to answer, since it really does depend upon so many things and is clearly an issue over which the experts can lose friends. I can only ever recall one research article that used a one-tailed test and the reality is that you would be unlikely to get published if you used them, or at least you would be asked to make corrections. Personally though, in project work, I can see no great tragedy lying in wait for those who do use one-tailed tests so long as they are conscientious, honest and professional in their overall approach to research, science and publishing. As a student, however, you should just pay attention to the following things:
- follow the universally accepted ‘rules’ given in the main text;
- be aware that this is a debate, and be prepared for varying opinions around it;
- try to test enough participants (as Bradley advises), pilot your design and tighten it, so that you are likely to obtain significance at p ≤ .01, let alone .05!
- the issue of two-tailed tests mostly disappears once we leave simple two-condition tests behind. In ANOVA designs there is no such issue.
For references, please see the textbook.
Calculating effect sizes and power in a 2-way ANOVA
In Chapter 21 of the book we calculated a two-way ANOVA on the data that are provided here in Exercise 1. The book tells you that you can obtain effect size and power using SPSS or G*Power, but that the by-hand calculations are rather complex. For the sake of completeness though I will give the detail here.
Remember we are dealing with an experiment where participants consume either strong coffee, decaffeinated coffee or nothing. These conditions are referred to as caffeine, decaff and none. Two groups of participants are tested, those who have just had five hours' sleep and those who have been awake for a full 24 hours. We therefore have a 2 (sleep) x 3 (caffeine) design. The results Table 21.2 from the book is:
Skill scores

Caffeine factor means x¯c1 = 5.125 x¯c2 = 4.25 x¯c3 = 4.0625 x¯g = 4.48 (grand mean)
Σx = 215
Σx2 = 1081
(Σx)2 = 46225
(Σx)2/N = 963.02 = C
* Overlong decimal figures are used here in order that our figures come close to those given by SPSS. With sensible rounding, our ANOVA results would be more different from the SPSS result than they are.
Table 21.2: Driving skill scores by caffeine and sleep conditions
Main effects
The general rules for calculating effect size and power for main effects in a two-way design are as follows, where we will refer to one factor with the general term A and the other with the term B.
For factor A,  = where αi is the difference between the grand mean and each mean for factor A ignoring any difference across factor B. Ideally, these means would be the true population means if known but in calculating power after an experiment we use the sample means and assume these are good estimates of the population means. For our caffeine/sleep study, then, the grand mean is 4.48 and the α values would be the differences between 4.48 and each value, that is, 5.13 (caffeine), 4.25 (decaff) and 4.06 (none). Each of these differences is squared, the results added and this result for the top of the equation is divided by a, the number of levels of A (three in the caffeine case) multiplied by the mean square for error (MSE) from the ANOVA calculation.
= where αi is the difference between the grand mean and each mean for factor A ignoring any difference across factor B. Ideally, these means would be the true population means if known but in calculating power after an experiment we use the sample means and assume these are good estimates of the population means. For our caffeine/sleep study, then, the grand mean is 4.48 and the α values would be the differences between 4.48 and each value, that is, 5.13 (caffeine), 4.25 (decaff) and 4.06 (none). Each of these differences is squared, the results added and this result for the top of the equation is divided by a, the number of levels of A (three in the caffeine case) multiplied by the mean square for error (MSE) from the ANOVA calculation.
Calculating for the caffeine effect we get:
 = 0.321
= 0.321
Our effect size, also referred to (by Cohen, 1988) as f, is 0.321. If we want to consult tables then we now need Φ which =  in general terms but with a factorial ANOVA we substitute n' for n where
in general terms but with a factorial ANOVA we substitute n' for n where  =1 1. Our df are broken down like this:
=1 1. Our df are broken down like this:
Total df = N – 1 = 47
Main effect (caffeine) df = 2
Main effect (sleep) df = 1
Interaction df = 2 x 1 = 2
Error df = 47 – 2 – 1 – 2 = 42
Hence 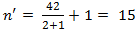 and Φ = 0.321√15 = 1.24
and Φ = 0.321√15 = 1.24
We go to appendix Table 13 with Φ = 1.24, df1 = 2 and dfe = 42 and α = 0.05. With a bit of extrapolation, we find that power is around 0.48 (don't forget that power = 1 – β). This is close enough to SPSS and G*Power which both agree on 0.471.
As explained in the book SPSS provides effect size and power if you select this before your analysis and in G*Power select F tests, ANOVA: Fixed effects, special, main effects and interactions and Post hoc: Compute achieved power - given α, sample size and effect size. The values to enter are 0.321 for effect size, .05 for α err probability, 48 for total sample size, 2 for numerator df and 3 for number of groups.
Interaction effects
For the interaction things are a bit tricky. The formula is  .
.
The calculation of ab is carried out for each individual cell of the data table. The calculation is: 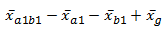 where
where  is the cell mean (5 hours/caffeine if working from the top left in table 1 above),
is the cell mean (5 hours/caffeine if working from the top left in table 1 above),  is the mean of the caffeine condition which that cell is in (caffeine and 5.125 in this case),
is the mean of the caffeine condition which that cell is in (caffeine and 5.125 in this case),  is the mean for the sleep condition of that cell (5 hours and 4.7917) and finally
is the mean for the sleep condition of that cell (5 hours and 4.7917) and finally  is the grand mean. Each of these six values (one for each of the cells in the table) is squared and the results are added together. This sum is divided by n' times the MSE where n' is calculated as above.
is the grand mean. Each of these six values (one for each of the cells in the table) is squared and the results are added together. This sum is divided by n' times the MSE where n' is calculated as above.
Put perhaps more simply for each cell you subtract from the cell mean the mean of the row it is in and the mean of the column it is in and then add the grand mean. Square the result and divide by n' times the MSE. Let's do this now. The calculation may look horrific but if you stick to the rule just stated you should be able to follow each step:
1. top line of the fraction inside the square root sign is:
(6.25 – 5.125 – 4.7917 + 4.48)2 + (4 – 5.125 – 4.1667 + 4.48)2 + (4.125 – 4.25 – 4.7917 + 4.48)2 +
(4.375 – 4.25 – 4.1667 + 4.48)2 + (4 – 4.0625 – 4.7917 + 4.48)2 + (4.125 – 4.0625 – 4.1667 + 4.48)2
Which comes to 1.983!
Dividing this by  we get: 1.983/(2 x 3 x 2.074) = 0.159
we get: 1.983/(2 x 3 x 2.074) = 0.159
The square root of 0.159 is 0.399. This is our value for Φ' (or f)
We need to calculate n' and we use  as above but here is for the interaction and hence dfcaffeine x dfsleep which is 2 x 1 = 2. Hence n' will again be 15.
as above but here is for the interaction and hence dfcaffeine x dfsleep which is 2 x 1 = 2. Hence n' will again be 15.
Φ then is Φ' x √n' = 0.399 x √15 = 1.54
Going to appendix Table 13 with Φ = 1.54, df for the interaction being 2, dferror = 42 and α = 0.05 we need (again) to do some extrapolation between the table values but I get a table value of around 0.35 and, remembering that power = 1 – β this gives power at 0.65 which is pretty close to the SPSS and G*Power values of 0.662. To use G*Power proceed exactly as given above but for the number of groups enter 6.