Practice Exercises
Use the links below to skip to a specific chapter:
Chapter 1 Chapter 2 Chapter 3 Chapter 4 Chapter 5 Chapter 6 Chapter 7 Chapter 8 Chapter 9 Chapter 10 Chapter 11 Chapter 12 Chapter 13 Chapter 14 Chapter 15 Chapter 16 Chapter 17 Chapter 18 Chapter 19 Chapter 20 Chapter 21 Chapter 22 Chapter 23 Chapter 24
Chapter 1 Psychology, science and research
Exercise 1.1

Reproduced from http://easyweb.easynet.co.uk/~philipdnoble/snow.html, courtesy of Philip Noble.
Some people say instantly ‘Oh it’s a picture of a man – so what?’. Many others (including me when I first encountered it) take a very long time to see a specific ‘thing’ in it. If you concentrate on the centre of the picture you should eventually see the top half of a man. If you imagine a beret right on top of the picture in the centre this would be correctly positioned on the man’s forehead and he would look a lot like Che Guevara. Many people have seen the picture as one of Christ with a long flowing beard. It could also be a cavalier. His face is lit as if from the right hand side and so there is a lot of shadow. If you have problems with it try looking at it with friends. Someone will spot it and help you to see the whole figure.
I won’t provide any precise detail on where it originates. It seems certain that it is a picture of ground and snow, possibly on a mountainside and probably taken in China or Japan. When I claimed (as I had been told) that it was a mountain one time, when teaching a class, a student told me it was taken by her grandfather and that it was in fact snow on a hedge. I had no reason to distrust the student but I have no independent evidence. Many people of course have claimed a ‘miraculous’ sighting of Christ but with Che Guevara, a cavalier and even Dave Lee Travis! All possible, you’ll have decide for yourself.
The main point of the demonstration though is this. When the man finally pops out at you, you will never again be able to see the picture as just a load of black and white blobs. You will have constructed and maintained a ‘template’ – a best bet as to what the picture is of – and this will remain as an automatic reaction in your perceptual system. Most of the time, in science and in everyday life, when we approach visual (and other sensory) material, we have a ‘best bet’ all ready and we are not aware of the perceptual system’s operation of ‘calculating’ what sensory data represent in the world.
Exercise 1.2
Give a meaning for, and an example of, the following words. Press ‘reveal’ to see some model answers. Hopefully your answers will be similar in meaning to these.
Deduction |
|
Empirical study |
|
Falsifiability |
|
Induction |
|
Sample |
|
Exercise 1.3
Disconfirming theories – a ‘lateral thinking’ problem
Pages 17–19 of the book discuss the attempt to disconfirm theories as a powerful aspect of scientific reasoning. One of the best ‘awkward’ problems I have come across is shown below. Read the problem and have a think before revealing the answer below.
Three philosophy professors (A, B and C) are applying for a prestigious chair of philosophy post. There is little to choose between them so the interview panel sets a logical reasoning task. The questioner gives the following instruction: ‘I am going to draw either a blue or a white spot on each of your foreheads. I will then reveal the spots to you all simultaneously. If you see a blue spot on another person’s head put your hand up. As soon as you think you can say what colour spot you have on your own forehead please speak up with your answer’. He proceeds to draw a blue spot on each forehead. When the spots are all revealed to the candidates each one, of course, puts up a hand. After a brief moment’s hesitation professor A lowers her arm and says ‘I must have a blue spot’. How did she work this out?
Problems like this one are sometimes included in the general group of ‘lateral thinking’ problems. However, you do not have to think ‘laterally’ or particularly creatively to get the answer. You do, however, have to kind of think upside down. Before rushing on to get the answer do try to think about how the professor knew what wasn’t true rather than how she knew what was true.
- + Show Answer
-
The answer is that she conducted a theory disconfirmation task. She thought ‘What if I had a white spot? If I did then B would quickly see that C could only have their arm up because B must have a blue spot, since my own spot, which each of them can see, would be white. But neither of them did respond quickly (remember all three are excellent at logical thinking) therefore I must have a blue spot.’ Professor A got the job!
Chapter 2 Measuring people – variables, samples and the qualitative critique
Exercise 2.1
Creating variables to measure psychological constructs
In this exercise try to give at least one operationally defined measure to assess the psychological construct in the list below. Examples are provided if you click ‘reveal’ but these are not the ‘correct’ answers, just some possibilities to demonstrate strict measurement.
|
Example answer: |
Anxiety |
|
Conformity |
|
Assertiveness |
|
Stress |
|
Self-esteem |
|
Exercise 2.2
Identifying sample types
Match the appropriate term with the sampling method described.
Interactive Quiz
Chapter 3 Experiments and experimental designs in psychology
Exercise 3.1
The nature of experiments
This is a True/False quiz to test your knowledge of the advantages of the experiment as a research method.
Interactive Quiz:
Exercise 3.2
Identifying experimental designs
In this short quiz you will need to read each research description and identify the specific experimental design.
Interactive Quiz:
Chapter 4 Validity in psychological research
Exercise 4.1
Tabatha and her validity threats
In this chapter of the book there is a description of a rather naff research project carried out by Tabatha. Here it is again. As you read this passage try to identify, and even name if possible, every threat to validity that she has either introduced or failed to control in her design. A list is provided in the answers below.
Tabatha feels she can train people to draw better. To do this, she asks student friends to be participants in her study, which involves training one group and having the other as a control. She tells friends that the training will take quite some time so those who are rather busy are placed in the control group and need only turn up for the test sessions. Both groups of participants are tested for artistic ability at the beginning and end of the training period, and improvement is measured as the difference between these two scores. The test is to copy a drawing of Mickey Mouse. A slight problem occurs in that Tabatha lost the original pre-test cartoon, but she was fairly confident that her post-test one was much the same. She also found the training was too much for her to conduct on her own so she had to get an artist acquaintance to help, after giving him a rough idea of how her training method worked.
Those in the trained group have had ten sessions of one hour and, at the end of this period, Tabatha feels she has got on very well with her own group, even though rather a lot have dropped out because of the time needed. One of the control group participants even remarks on how matey they all seem to be and that some members of the control group had noted that the training group seemed to have a good time in the bar each week after the sessions. Some of her trainees sign up for a class in drawing because they want to do well in the final test. Quite a few others are on an HND Health Studies course and started a module on creative art during the training, which they thought was quite fortunate.
The final difference between groups was quite small but the trained group did better. Tabatha loathes statistics so she decides to present the raw data just as they were recorded. She hasn’t yet reached the recommended reading on significance tests in her RUC self-study pack.
Possible threats to validity in the study:
- + Show Answer
-
Name of threat
Issue in text
Non-equivalent groups
Busy students go into the control group.
Non-equivalent measures
Different Mickey Mouse pre- and post-test; a form of construct validity threat.
Non-equivalent procedures
Training method not clearly and operationally defined for her artist acquaintance.
Mortality
More participants dropped out of the training group than from the control group.
Rivalry
Control group participants note – some trainee group participants go for extra training in order to do well.
History effect
Some participants in the training group receive creative art training on their new HND module.
Statistical conclusion validity
Not a misapplication of statistical analysis but no analysis at all!
Exercise 4.2
Spotting the confounding variables
A confounding variable is one that varies with the independent (or assumed causal) variable and is partly responsible for changes in the dependent variable, thus camouflaging the real effect. Try to spot the possible confounding variables in the following research designs. That is, look for a factor that might well have been responsible for the difference or correlation found, other than the one that the researchers assume is responsible. If possible, think of an alteration to the design that might eliminate the confounding factor. Possible factors will be revealed under each example.
a. Participants are given either a set of 20 eight-word sentences or a set of 20 sixteen-word sentences. They are asked to paraphrase each sentence. At the end of this task they are unexpectedly asked to recall key words that appeared in the sentences. The sixteen-word sentence group performed significantly worse. It is assumed that the greater processing capacity used in paraphrasing sixteen words left less capacity to store individual words.
- + Show Answer
- Could be the extra time taken by the second task caused greater fatigue or confusion
b. Male and female dreams were recorded for a week and then analysed by the researcher who was testing the hypothesis that male dream content is more aggressive than female dream content
- + Show Answer
- The researcher knew the expected result, hence researcher expectancy is a possible cause of difference. Solution is to introduce a single blind.
c. People who were fearful of motorway driving were given several sessions of anxiety reduction therapy involving simulated motorway driving. Compared with control participants who received no therapy, the therapy participants were significantly less fearful of motorway driving after a three-month period.
- + Show Answer
- There was no placebo group. It could be that the therapy participants improved only because they were receiving attention. Need an ‘attention placebo’ group.
d. After a two-year period depressed adolescents were found to be more obese than non-depressed adolescents and it was assumed that depression was the major cause of the obesity increase.
- + Show Answer
- Depression will probably correlate with lowered physical activity and this factor may be responsible. Needs depressed adolescents to be compared with similarly inactive non-depressed adolescents.
e. People regularly logging onto Chat ’n Share, an internet site permitting the sharing of personal information with others on a protected, one-to-one basis, were found to be more lonely after one year’s use than non-users. It was assumed that using the site was a cause of loneliness.
- + Show Answer
- Those using the site had less time to spend interacting with other people off-line; need to compare with people spending equal time on other online activities.
f. Participants are asked to sort cards into piles under two conditions. First they sort cards with attractive people on them, then they sort ordinary playing cards. The first task takes much longer. The researchers argue that the pictures of people formed an inevitable distraction, which delayed decision time
- + Show Answer
- Order effect! The researcher has not counter-balanced conditions. The participants may simply have learned to perform the task faster in the second condition through practice on the first.
g. It is found that young people who are under the age limit for the violent electronic games they have been allowed to play are more aggressive than children who have only played games intended for their age group. It is assumed that the violent game playing is a factor in their increased aggression.
- + Show Answer
- This is only a correlation and there may be a third causal variable that is linked to both variables. Perhaps the socio-economic areas in which children are permitted to play under age are also those areas where aggression is more likely to be a positive social norm.
Chapter 5 Quasi-experiments and non-experiments
Exercise 5.1
Some outlines of research studies are given below and your task is to decide which one of the following research designs each study used (some of which are taken from previous exercises). In the absence of specific information assume studies are conducted in a laboratory.
Research design |
Full description |
Lab experiment (true) |
True experiment conducted in a laboratory. |
Lab quasi |
Quasi experiment conducted in a laboratory. |
Lab non-experiment |
Non-experiment conducted in a laboratory. |
Field experiment (true) |
Field experiment (true). |
Field quasi |
Field quasi experiment. |
Field non-experiment |
Field research study, which is not an experiment. |
1. A researcher’s confederate sang identical songs on two separate days, one day dressed scruffily and the other day smartly dressed. Passers-by were asked to rate the busker’s performance on the two separate days.
- + Show Answer
- Field quasi
2. Participants were allocated at random to one of two conditions of an experiment. In one condition participants were asked to learn a list of 20 words with accompanying pictures. In the other condition, the participants were asked to learn the words without the pictures.
- + Show Answer
- Lab experiment (true)
3. Children in a nursery were randomly allocated either to a condition where they were shown a film in which several adults behaved quite aggressively or to a condition in which they were shown a nature film. Both groups were then observed for aggressive behaviour.
- + Show Answer
- Field experiment (true)
4. Male and female dreams were recorded at home by participants for a week and then analysed by a researcher who was testing the hypothesis that male dream content is more aggressive than female dream content.
- + Show Answer
- Field non-experiment
5. People attending a health clinic and who were fearful of motorway driving were given several sessions of anxiety reduction therapy involving simulated motorway driving. A control group was formed by people on a waiting list who had only recently applied for therapeutic help with the same problem. The therapy participants were significantly less fearful of motorway driving after a three-month period than the control group.
- + Show Answer
- Field quasi
6. People who had recently experienced a post-traumatic stress disorder were asked by a psychological researcher to undergo a battery of psycho-motor test trials. Compared with non-stressed participants the performed significantly worse.
- + Show Answer
- Lab non-experiment
7. Psychology students were invited to volunteer for a research study. Because the researcher did not want participants from one condition to discuss the procedure with participants in the other, he asked students from one course to detect stimuli under stressful condition and student from the other course to do the same task under non-stressful conditions.
- + Show Answer
- Lab quasi
Chapter 6 Observational methods – watching and being with people
Exercise 6.1
Defining some key terms used in the chapter
Can you give a meaning for the following terms? Click to see a model answer. Hopefully your answers will be similar in meaning to these.
|
Give a meaning for the following: |
Possible answer: |
Archival data |
|
Case study |
|
Coding |
|
Diary method |
|
Inter-observer reliability |
|
Naturalistic observation |
|
Participant observation |
|
Reactivity |
|
Structured observation |
|
Chapter 7 Interview methods – asking people direct questions
Exercise 7.1
Preparing an interview schedule
Prepare a set of questions for an interview investigating the issue of assisted suicide. Imagine that this is for a piece of qualitative research where you wish to explore the concept fully in terms of people’s attitudes to the issue. You particularly want to know how people rationalise their positions. Make sure that your questions cover a wide area of possible perspectives – look at the issue from different people’s points of view. After you have prepared your interview schedule as fully as you think you can, have a look at the points below (click the ‘reveal hints’ buttons) and see if you have covered all these areas and perhaps produce some that I didn’t think of.
- + Hint 1
- How many of your questions will, produce short answers (e.g., ‘do you believe in assisted suicide?’ or ‘would you ever assist someone to commit suicide?’ – these are closed questions and may only produce single answers of ‘yes’ or ‘no’).
- + Hint 2
- Have you used prompts and probes to facilitate elaboration of shorter answers? (e.g., ‘If no, could you tell me why?’
- + Hint 3
- Have you investigated:
- The conditions under which your interviewee would agree to assist or agrees with assisted suicide – e.g., how many months to live, how much certainty of pain, etc., for degenerative diseases or just when life is unbearable?
- Their reasons for wanting or not wanting to assist.
- Their reasons for accepting or rejecting the idea.
- The perspective of the potential suicide, the assister, the immediate family of the dying person?
- The effect that publicised suicides might have on other people.
- Whether the interviewee would follow the law of the land (and therefore think it permissible to assist suicide in countries where this is legal).
- To what extent is the assister legally culpable?
- The feelings of people assisting a loved one to suicide.
- The implications of the Hippocratic oath and doctors’ commitment to sustaining life.
- … or does the commitment to care include helping people escape pain and indignity?
- The position of carers and whether sufficient support is available for them.
- The issue of whether we should wait for technological advances, e.g., in the area of pain relief.
- How much medical opinion should be sought – at least two doctors (e.g.)?
- The issue of maintaining dignity.
- Whether suicide is ‘cowardly’, ‘selfish’ or an act of ‘bravery’, ‘courageous’.
- The sanitisation of death – so it is kept away from us most of the time.
- Whether removing life sustaining support is assisting suicide or ‘murder’.
- The issue of control – who should decide to maintain life if a person wants to end theirs.
- Religious reasons or arguments for views.
- Have you teased out arguments for and/or against rather than just isolated views?
Exercise 7.2
Defining some key terms used in the chapter
Can you give a meaning for the following terms? Click to see a model answer. Hopefully your answers will be similar in meaning to these.
Give a meaning for the following: |
|
Closed questions |
|
Focus group |
|
Open questions |
|
Panel |
|
Semi-structured interview |
|
Survey |
|
Chapter 8 Psychological tests and measurement scales
Exercise 8.1
Problematic items in psychological scales
Some proposed items for different kinds of psychological scales are listed below. In each case select the kind of error (from the list in the box below) that is being made with the item (see p. 207 of the book for explanations).
Leading question |
Ambiguous |
Technical terms |
(too) Complex |
(too) Emotive |
(too) Personal |
Double-barrelled |
Double negative |
Inappropriate scale |
1. Violent video games can have a negative effect on children’s socio-psychological development.
- + Show Answer
- technical terms
- + Show Explanation
- Would respondents understand socio-psychological?
2. Boxers earn a lot of money (in an attitude to boxing scale).
- + Show Answer
- ambiguous
- + Show Explanation
- That boxers earn a lot of money is a fact but it gives no indication of a person’s views on boxing. Both sides will agree so the item has no discriminatory power.
3. Boxing is barbaric and should be banned.
- + Show Answer
- double barrelled
- + Show Explanation
- May agree it is barbaric but argue against a ban.
4. Hunters should not terrify poor defenceless little animals.
- + Show Answer
- emotive
- + Show Explanation
- Could be an item in some scales but is a bit OTT on emotional tugging here.
5. I thought the advertisement was:
Good Average Poor Very Poor
- + Show Answer
- inappropriate scale
- + Show Explanation
- There are two negative ‘poor’ choices but only one positive choice. Also, what is meant by ‘average’?
6. Have you ever suffered from a mental disorder?
- + Show Answer
- too personal
- + Show Explanation
- Should not need to ask this and may not get an honest reply. Might be relevant in specialised research but would probably not be approached so bluntly.
7. People have a natural tendency to learn though encountering problems, seeking information and testing hypotheses about the world and therefore education should be about providing resources for discovery rather than about top-down delivery and testing of knowledge.
Answer:
- + Show Answer
- too complex
- + Show Explanation
- Though the statement makes sense it may well need reading a few times and may tax some respondents with its vocabulary and length.
8. Don’t you think the government will miss its child poverty targets?
- + Show Answer
- leading question
- + Show Explanation
- Probably wouldn’t be as blatantly leading as this but even ‘Do you think…’ invites agreement.
9. There are no grounds upon which a child should not be given a right to education.
- + Show Answer
- double negative
- + Show Explanation
- Should be understood by most but double negatives do make respondents have to think twice.
Exercise 8.2
Defining some key terms used in the chapter
Can you give a meaning for the following terms? Click to see a model answer. Hopefully your answers will be similar in meaning to these.
Chapter term |
Explanation |
External reliability |
|
Factor analysis |
|
Internal reliability |
|
Psychometric test |
|
Response acquiescence |
|
Standardisation |
|
Validity |
|
Chapter 9 Comparison studies – cross sectional, longitudinal and cross-cultural studies
Exercise 9.1
Defining some key terms used in the chapter
Can you give a meaning for the following terms? Click to see a model answer.
Give a meaning for the following: |
|
Cohort effect |
|
Cross-generational problem |
|
Cross-sectional study |
|
Cross-cultural study |
|
Cross-lagged correlation |
|
Cultural relativity |
|
Longitudinal study |
|
Panel design |
|
Time-lag study |
|
Chapter 10 Qualitative approaches in psychology
Exercise 10.1
Matching approaches to principles
Chapter 10 introduces several well-defined approaches to the collection and analysis of qualitative data that have developed over the last few decades. Below are brief descriptions of the principles of each approach. For each one, try to select the appropriate approach from the list below.
Grounded theory |
Interpretive phenomenological analysis |
Discourse analysis |
Thematic analysis |
Ethnography |
Action research |
Narrative analysis |
1. An approach that encourages the development of theory through the data emerging from the analysis of qualitative data patterns and are not imposed on the data before they are gathered. Data are analysed until saturated.
- + Show Answer
- grounded theory
2. This approach holds that what people say is not a source of evidence for what they have in their heads or minds. It analyses speech as people’s ways of constructing their perceptions and memories of the world as they see it. Speech is used to construct one’s ‘stake’.
- + Show Answer
- discourse analysis
3. In this approach an organisation or a culture is studied intensively from within.
- + Show Answer
- ethnography
4. An approach that analyses text for themes and which can be theory driven (theory emerges from the data) or top-down (testing hypotheses or seeking to confirm previous findings and theories). Highly versatile and not allied to any specific philosophical position.
- + Show Answer
- thematic analysis
5. This approach sees the role of psychological research as one of intervention to produce change for human benefit. An important aspect of the approach is the emphasis by the researcher on a collaborative project.
- + Show Answer
- action research
6. In this approach researchers try to access the perceptions and thoughts of the researched persons and to reflect and understand these in a way that is as close as possible to the way that the persons themselves interpret the world. The data analysis is usually a search for themes among interview data.
- + Show Answer
- Interpretive phenomenological analysis
7. This approach studies the ways in which people construct memories of their lives through stories. A central principle is that people generally establish their identity through the method of construction through re-telling even if this is to themselves.
- + Show Answer
- narrative analysis
Exercise 10.2
Defining some key terms used in the chapter
Can you give a meaning for the following terms? Click to see a model answer.
Give a meaning for the following: |
|
Constructivism |
|
Endogenous research |
|
Feminist psychology |
|
Paradigm |
|
Realism |
|
Reflexivity |
|
Theoretical sampling |
|
Chapter 11 Ethical issues in psychological research
Exercise 11.1
Ethical issues in research designs
What are the main ethical issues involved in the following possible research designs? Please have a good think before you reveal the answers.
1. A researcher arranges for shoppers to be given either too much or too little change when making a purchase in a department store. A record is taken of how many return to the cash desk and those that do are asked to complete a short questionnaire and are then debriefed as to the purpose of the study.
- + Show Answer
- The ‘participants’ in this study were not able to give their informed consent before participating. They have been mildly delayed by having to return to the cash desk but are also under undue pressure to then complete the questionnaire.
2. Participants are given a general intelligence test and are then given false feedback about their performance. They are told either that they did very well and significantly above average or that they did rather poorly and significantly below average.
- + Show Answer
- There is a possible issue of some psychological harm in that some participants are told they have produced poor intelligence scores. OK – the effect is short-lived, but psychologists have to consider whether the knowledge gained from the experiment will be worth the perhaps mild distress caused to the participants but also the effect this has on the credibility and trustworthiness of psychologists in general, in the public view.
3. In-depth semi-structured interviews are conducted with seven middle managers in an organisation where there has been some discord between middle and senior management. The researcher has been contracted to highlight possible causes of resentment and reasons for frustration that have been expressed quite widely. The researcher published a full report including demographics of the participants three of whom are women, one of whom one is Asian.
- + Show Answer
- There is a problem here with anonymity. It will be easy for the senior managers to identify the sole Asian woman. In cases like these full information has to be compromised in order to preserve privacy and to protect individuals whose lives could be seriously affected by disclosure.
4. Participants volunteer for an experiment and are first shown slides that have a theme of sweets, nuts or beans. They are then asked to put their hands into bags which contain either jelly beans, peanuts or kidney beans. The researcher is interested in whether the slides influence the participant’s identification of the items in the bag.
- + Show Answer
- The description does not make clear whether the participants were asked before participating whether they might suffer from any allergies. Most importantly there is a risk of an anaphylactic reaction from the peanuts. This then is in contravention of the principle of not putting participants at any physical risk.
5. A researcher conducting an experiment is quite attracted to one of the participants. At the end of the session, when the experiment is over, he asks her for a date.
- + Show Answer
- The researcher is in a position of special power over the participant and should not exploit this by mixing professional activity with personal life. The two might of course meet up somehow outside the professional context but making this approach in the context of the experiment puts the psychologist at risk of contravening professional ethics.
Chapter 12 Analysing qualitative data
Exercise 12.1
Defining some key terms used in the chapter
Can you give a meaning for the following terms? Click to see a model answer.
Analytic induction |
|
Analytic procedure |
|
Coding unit |
|
Content analysis |
|
Idiographic |
|
Nomothetic |
|
Inductive analysis |
|
Respondent validation or ‘member checking’ |
|
triangulation |
|
Chapter 13 Statistics – organising the data
The early part of Chapter 13 introduces levels of measurement and first talks of categorical and measured variables. We then look at the traditional division of scales into four types, nominal, ordinal, interval and ratio. In fact, when attempting the analysis of data and trying to decide which statistical treatment is appropriate you will never need to decide whether data are at a ratio level and you will rarely come across ordinal level data. There are two major decisions most of the time: first, whether your variable for analysis is categorical or measured; and second, if measured, whether it can safely be treated as interval level data or whether you should employ tests that are appropriate for ordinal level data. We deal with these distinctions here but they will be put into practice when deciding whether data are suitable for parametric testing as described in Chapter 19.
Exercise 13.1
Identifying categorical and measured variables
Decide in each case below the type of variable for which data have been recorded: Categorical or Measured. Questions 1, 5, 9, 10 and 11 have further explanations that can be found by clicking on the reveal button.
1. Numbers of people who are extroverted or introverted
- + Show Answer
- categorical
- + Show Explanation
- The numbers of people counted are on an interval scale but for each participant we have only a category; never confuse the frequencies with the measurement method used for each person/case.
2. Scores on an extroversion scale
- + Show Answer
- measured
3. Number of words recalled from a learned 20 item list
- + Show Answer
- measured
4. Whether people stopped at a red traffic light or not
- + Show Answer
- categorical
5. Grams of caffeine administered to participants
- + Show Answer
- measured
- + Show Explanation
- Grams are units on a clearly measured scale. However, we could be conducting an experiment where we give 0 grams 50 grams or 200 grams to participants, in which case we would be using three categories; it is always possible to use an interval scale but create categories like these. If, for instance, we recorded in each case only whether participants solved a problem or not we would have a 3 x 2 cross tabs table for a c2 analysis – see Chapter 18.
6. Number of errors made in completing a maze
- + Show Answer
- measured
7. Whether people were recorded as employed, self-employed, unemployed or retired
- + Show Answer
- categorical
8. Number of cigarettes smoked per day
- + Show Answer
- measured
9. Whether people smoked none, 1–15, 15–30, or more than 30 cigarettes per day
- + Show Answer
- categorical
10. Number of aggressive responses recorded by an observer of one child
- + Show Answer
- measured
- + Show Explanation
- Here again a measured variable has been reduced to a set of categories.
11. Whether a child was recorded as strong aggressive or moderate aggressive or non-aggressive
- + Show Answer
- categorical
- + Show Explanation
- The same thing could have happened here too.
Exercise 13.2
Finding descriptive statistics
For those able to use IBM SPSS or any other spreadsheet software that will find descriptive statistics the file psychology test scores.sav (SPSS) or psychology test scores.xls (Excel) contains data on 132 cases that you can work with. For those working by hand this is rather a lot of data so I have provided a smaller data set below for you.
Download Exercise 13.2 Data sets
Working on SPSS or equivalent with the psychology test score data find the:
Mean
- + Show Answer
- 37.02
Median
- + Show Answer
- 38
Mode
- + Show Answer
- 39
Range
- + Show Answer
- 3
- + View Note
- 1 has been added to the SPSS answer for the range (37) for the reasons given on p. 352 of the book. We assume the range runs from the lower end of the lower interval to the upper end of the upper interval.
Semi-interquartile range
- + Show Answer
- 3.5
- + View Note
- Find the semi-interquartile range in SPSS by selecting Analyze/Descriptives/Frequencies and selecting the statistics box to select quartiles. The output will call these ‘percentiles’ but the 25th and 75th will be provided so you can take the difference between these two and halve it.
Standard deviation
- + Show Answer
- 6.83
Click on each item to see the correct answer.
For those working by hand here is a simpler data set:
14 15 16 18 18 19 21 22 22 22 23 23 23 24 24 25 25 26 27 27 35 38 39
Try to calculate the same statistics (and read the notes above about calculations):
Mean
- + Show Answer
- 23.65
Median
- + Show Answer
- 23
Mode
- + Show Answer
- 22
Range
- + Show Answer
- 27
Semi-interquartile range
- + Show Answer
- 3.5
- + View Note
- Excel gives slightly different answers for quartiles and percentiles and hence the semi-interquartile range value will be different – 2.75
Standard deviation
- + Show Answer
- 6.58
Click on each item to see the correct answer.
Chapter 14 Graphical representation of data
Exercise 14.1
A bar chart
Students on an organisational psychology course have taken part in an experiment in which they have first conducted an interview while being observed by a visiting lecturer. Half the students are told the visitor was an expert in human relations and half of this group are given positive feedback by the visitor while the other half are given negative feedback. The other half of the students are told their visiting observer is simply ‘an academic’ and the same two types of feedback are given by the visitor to this group. Students were then asked to rate their own interview performance on a scale of 1 (very poor) to 10 (excellent). The results are displayed in the combined bar chart below.
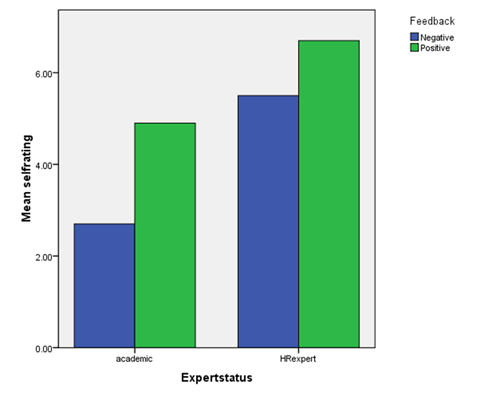
Please describe the results as accurately as you can (no specific numerical values are required) and offer some possible explanation of the findings.
- + Show Answer
- In general positive feedback has greater effect than negative feedback. In addition there appears to be a greater effect from the expert than from the academic. However, there also seems to be an interaction in that the academic’s negative feedback appears to have had a greater lowering effect than that of the expert. Perhaps the students receiving expert negative feedback would rationalise that the expert would be particularly harsh and have therefore discounted some of the feedback.
Exercise 14.2
A histogram
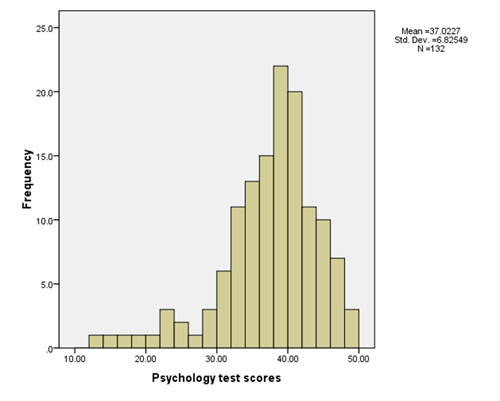
A psychology lecturer has given her students a class test where the maximum mark possible is 50. The histogram above shows the distribution of the test score data. The median of this distribution is 38:
1. Was the test easy or hard?
- + Show Answer
- Easy. The distribution is negatively skewed and shows a ‘ceiling effect’ with many scores near the top end of the scale.
2. Why is the mean lower than the median?
- + Show Answer
- Because the distribution is negatively skewed and therefore there are more extreme low scores in the tail pulling the mean (37.02) lower than the median (38).
3. What is the modal category of scores?
- + Show Answer
- 38–40
Note: The data for this histogram are contained in the file used in the Chapter 13 exercises.
Chapter 15 Frequencies and distributions
Exercise 15.1
z scores
A reading ability scale has a mean of 40 and a standard deviation of 10 and scores on it are normally distributed.
1. What reading score does a person get who has a z score of 1.5?
- + Show Answer
- 55
2. If a person has a raw score of 35 what is their z score?
- + Show Answer
- -0.5
3. How many standard deviations from the mean is a person achieving a z score of 2.5?
- + Show Answer
- 2.5 above the mean
4. What percentage of people score above 50 on the test?
- + Show Answer
- 15.87%
5. What percentage of people score below 27?
- + Show Answer
- 9.68%
6. What is the z score and raw score of someone on the 68th percentile?
- + Show Answer
- z is where 18% (or .18) are above the mean. z is .47 and this is 4.7 above 40 = 44.7
7. At what percentile is a person who has a raw score of 33?
- + Show Answer
- 24th (24.2%)
Exercise 15.2
Standard error
1a. If a sample of 30 people produces a mean target detection score of 17 with a standard deviation of 4.5, what is our best estimate of the standard error of the sampling distribution of similar means?
- + Show Answer
- 1.006
- + Show Explanation
-
Use
 =
= 
1b. Using the result of question a), find the 95% confidence interval for the population mean.
- + Show Answer
- 15.39 to 18.61
- + Show Explanation
- For 95% limits z must be -1.96 to +1.96; 1.96 x the se = 1.96 x 0.82 = 1.61
Hence we have 95% confidence that the true mean lies between 17 ± 1.61
Chapter 16 Significance testing – was it a real effect?
Exercise 16.1
One- or two-tailed tests
In each case below decide whether the research prediction permits a one-tailed test or whether a two-tailed test is obligatory.
1. There will be a difference between imagery and rehearsal recall scores.
- + Show Answer
- two-tailed
2. Self-confidence will correlate with self-esteem
- + Show Answer
- two-tailed
3. Extroverts will have higher comfort scores than introverts
- + Show Answer
- one-tailed
4. Children on the anti-bullying programme will improve their attitude to bullying compared with the control group
- + Show Answer
- one-tailed
5. Children on the anti-bullying programme will differ from the control group children on empathy
- + Show Answer
- two-tailed
6. Anxiety will correlate negatively with self-esteem
- + Show Answer
- one-tailed
7. Participants before an audience will make more errors than participants alone
- + Show Answer
- one-tailed
8. Increased caffeine will produce a difference in reaction times
- + Show Answer
- two-tailed
Exercise 16.2
Type I and Type II errors
Please answer true or false for each item.
Interactive Quiz:
Exercise 16.3
z values and significance
In the chapter we looked at a value of z and found the probability that a z that high or higher would be produced at random under the null hypothesis. We do that by taking the probability remaining to the right of the z value on the normal distribution in Appendix table 2 (if the z is negative we look at the other tail as in a mirror). Following this process, in the table below enter the exact value of p that you find from Appendix table 2. Don’t forget that with a two-tailed test we use the probabilities at both ends of the distribution. Enter your value with a decimal point and four decimal places exactly as in the table. Decide whether a z of this value would be declared significant with p £ .05
|
z value |
One or Two tailed |
p = |
Significant? |
a |
0.78 |
One |
|
|
b |
1.97 |
Two |
|
|
c |
2.56 |
Two |
|
|
d |
-2.24 |
Two |
|
|
e |
1.56 |
One |
|
|
f |
-1.82 |
Two |
|
|
- + Show Answer
-
z value
One or Two tailed
p =
Significant?
a
0.78
One
.2177
No
b
1.97
Two
.0488
Yes
c
2.56
Two
.0104
Yes
d
-2.24
Two
.0250
Yes
e
1.56
One
.0594
No
f
-1.82
Two
.0688
No
Chapter 17 Testing for differences between two samples
Here are the data sets, in SPSS and in MS Excel, for the results that are calculated by hand in this chapter of the book. The related t, unrelated t and single sample t data sets are all contained in the Excel file t test data sheets.xls. The files in SPSS are unrelated t sleep data.sav, related t imagery data.sav and single sample t test data.sav.
Download Exercise 17.1 Data sets
unrelated t sleep data.sav
related t imagery data.sav
single sample t test data.sav
t test data sheets.xls
The data files for the non-parametric tests are linked below. The excel file nonparametric test data.xls contains the data for the Mann-Whitney, Wilcoxon and Sign test calculations. The SPSS files are, respectively, mannwhitney stereotype data.sav, wilcoxon module ratings data.sav and sign test therapy data.sav.
Download Exercise 17.1 Data sets
mannwhitney stereotype data.sav
wilcoxon module ratings data.sav
sign test therapy data.sav
nonparametric test data.xls
Exercise 17.1
t tests on further data sets
Download Exercise 17.1 Data sets
t test scenario 1 data.sav
t test scenario 2 data.sav
t test scenario 3 data.sav
t test scenario data.xls
Data sets are provided here that correspond with the three research designs described below. Your first task is to identify which type of t test should be performed on the data for each design: unrelated t test, related t test, or single sample t test.
Scenario 1: Participants are asked to solve one set of anagrams in a noisy room and then solve an equivalent set in a quiet room. The prediction is that participants will perform worse in the noisy room. Data are given in seconds.
- + Show Answer
- related t test
Scenario 2: A sample of children is selected from a ‘free’ school where the educational policy is radically different from the norm and where students are allowed to attend classes when they like and are also involved in deciding what lessons will be provided by staff. It is suspected their IQ scores may be lower than the average.
- + Show Answer
- single sample t test
Scenario 3: One group of participants is asked to complete a scale concerning attitudes to people with disabilities. A second group of children is shown a film about the experiences of people with disabilities and then asked to complete the attitude scale a week later. The research is trying to show that changes in attitude last beyond the limits of the typical short-term laboratory experiment.
- + Show Answer
- Unrelated t test
Now conduct the appropriate test on each data set and give a full report of the result including: t value, df, p value (either exact or in the ‘p less than …’ format), 95% confidence limits for the mean difference and effect size.
- + Show Answer
-
Scenario 1 (related t)
The mean time to solve anagrams in the noisy room (M = 193.45 secs, SD = 43.16) was higher than the mean time for the quiet room (M = 178.25, SD = 24.52) resulting in a mean difference of 15.2 seconds. This difference was not significant, t (19) = 1.558, p = .136. The mean difference (95% CI: -5.22 to 35.62) was small (Cohen’s d = 0.35).Scenario 2 (single sample t )
The ‘free’ school children had a lower mean than the standard average IQ of 100 (M = 97.7, SD = 9.5). This difference, however, was not significant, t (24) = 1.22, p = .236.The difference between the sample mean and the population mean was small (2.32, 95% CI: -6.26 to 1.62, Cohen’s d = 0.15).
Note that here the known population standard deviation of 15 points has been used, so d is 2.32/15 = 0.15
Scenario 3 (unrelated t)
The film group produced a higher mean attitude score (M = 25.65, SD = 5.25) than the control group (M = 22.2, SD = 4.76). The difference between means was significant, t (38) = 2.18, p = .036. The difference between means (difference = 3.45, 95% CI: 0.24 to 6.66) was moderate (Cohen’s d = 0.69).Note: Effect size is calculated using
 where s is the mean standard deviation for the two groups ( sample sizes are equal).
where s is the mean standard deviation for the two groups ( sample sizes are equal).
Exercise 17.2
Non-parametric tests on the scenario data sets
Select below the appropriate non-parametric tests that can be used on the Scenario 1 and 3 data from the t test exercises. In one scenario more than one appropriate test can be selected.
Scenario 1 (Anagrams in noisy and quiet rooms)
Wilcoxon Mann-Whitney Sign test
- + Show Answer
- Wilcoxon and Sign test
Scenario 3 (Control and film groups’ attitudes towards disabled people)
Wilcoxon Mann-Whitney Sign test
- + Show Answer
- Mann-Whitney
Now conduct the appropriate test on each data set and give a full report of the result including: T or U, appropriate N values, p value (either exact or in the ‘p less than …’ format) and effect size.
- + Show Answer
-
Scenario 1: (Wilcoxon)
The differences between time taken to solve anagram in the noisy room and time taken in the quiet room were ranked according to size for each participant. A Wilcoxon T analysis on the difference ranks showed a rank total of 139 where noisy room times were higher than quiet room times and a rank total of 71 where quiet room times were higher. Hence, quiet rooms times were generally lower than noisy room times but this difference was not significant, T (N = 20) = 71, p = .204. The estimated effect size was small to moderate, r= 0.28.Scenario 1 (Sign test)
For each participant the difference between noisy room and quiet room time was found and the sign of this difference recorded. The 13 cases where quiet room score was less than noisy room score were contrasted with the 7 cases where the difference was in the opposite direction using a sign test analysis. The difference was found not to be significant with S (N = 20) = 7, p = .263.Scenario 3: Mann-Whitney
The children’s disability attitude scores were ranked as one group. The rank total for the control group was 339.5 whereas the total for the film trained group was 480.5. Using a Mann-Whitney analysis significance was very nearly achieved with U (N = 40)= 129.5, p = .056. The effect size was moderate, r = 0.3
Chapter 18 Tests for categorical variables and frequency tables
Exercise 18.1
A 2 x 2 chi-square analysis
Individual passers-by, approaching a pedestrian crossing, are targeted by observers who record whether the person crosses against the red man under two conditions, when no one at the crossing disobeys the red man and when at least two people disobey. The results are recorded in the table below.
|
No jaywalker |
At least two jaywalkers |
|
Target disobeys light |
16 |
27 |
43 |
Target obeys light |
43 |
33 |
76 |
|
59 |
60 |
119 |
1. Calculate the expected frequencies for a chi-square analysis. Copy the table below and enter your results.
|
No jaywalker |
At least two jaywalkers |
|
Target disobeys light |
|
|
43 |
Target obeys light |
|
|
76 |
|
59 |
60 |
119 |
2. Now conduct the chi-square analysis. The data set has not been supplied here since the data are so simple. However, if using SPSS don’t forget to weight cases as described on p. 501 of the book. You need a variable called jaywalkers with two values, ‘none’ and ‘two’. You need a second variable, obeys, with two values ‘no’ and ‘yes’. Make your datasheet show one case for each possible combination and enter the appropriate data into a third column called count. Then select Data/Weight cases and drop the variable count into the weight cases box to the right.
Now enter your result into the spaces below. In each case use three places of decimals and don’t worry if you’re a fraction out. This could be because of rounding decimals in your calculations.
c2 (1, N = 119) |
|
p value |
|
- + Show Answer
-
1.
No jaywalker
At least two jaywalkers
Target disobeys light
37.7
38.3
43
Target obeys light
21.3
21.7
76
59
60
119
2.
c2 (1, N = 119)
4.122
p value
.042
Exercise 18.2
A loglinear analysis
Suppose that the research in Exercise 18.1 is extended to include an extra condition of five or more jaywalkers and to include a new variable of gender. The table below gives fictitious data for such an observational study. Conduct a loglinear analysis on the data outlining all significant results in your results report.
Males |
|
|
|
|
|
No jaywalker |
At least two jaywalkers |
Five or more jaywalkers |
|
Target disobeys light |
21 |
25 |
38 |
84 |
Target obeys light |
38 |
35 |
22 |
95 |
|
59 |
60 |
59 |
179 |
Females |
|
|
|
|
|
No jaywalker |
At least two jaywalkers |
Five or more jaywalkers |
|
Target disobeys light |
22 |
23 |
29 |
74 |
Target obeys light |
39 |
37 |
31 |
107 |
|
61 |
60 |
60 |
181 |
- + Show Answer
-
A three-way backward elimination loglinear analysis was performed on the frequency data in the table above produced by combining frequencies for jaywalkers, obedience and gender. One-way effects were not significant, likelihood ratio c2 (4) = 5.40, p = .248; two-way effects were significant, likelihood ratio c2 (5) = 11.968, p = .035; the three-way effect was not significant, c2 (2) = 1.789, p = .409. Only the jaywalkers x obedience interaction was significant c2 (2) = 10.845, p = .004. More people crossed against the light when there were more jaywalkers present.
Chapter 19 Correlation and regression
Exercise 19.1
Scatter plots
Have a look at the scatter plots below and select a description in terms of strength (weak, moderate, strong) and direction (positive, negative or curvilinear).
Figure 1

Figure 2

Figure 3

- + Show Answer
-
Figure 1: strong, positive
Figure 2: moderate, negative
Figure 3: strong, curvilinear
Exercise 19.2
Calculating Pearson’s and Spearman’s correlations
You’ll need these data sets for this exercise
Download Exercise 19.2 Data sets
correlation.sav
correlation.xls
The data set in the file correlation.sav (SPSS) or correlation.xls (Excel) is for you to use to calculate Pearson’s rand Spearman’s r(two-tailed) either by hand or using SPSS or a spreadsheet programme.Copy the table below and enter, using either p = or p £.
Don’t worry if your answer is out by a small amount as this might be due to rounding errors.
Pearson’s r = |
|
p = |
p £ |
Spearman’s r = |
|
p = |
p £ |
- + Show Answer
-
(please note negative values for correlations)
Pearson’s r =
-.48
p = 0.005
p £ 0.01
Spearman’s r =
-.492
p = 0.004
p £ 0.01
Exercise 19.3
A few questions on correlation
1. Jarrod wants to correlate scores on a general health questionnaire with the subject that students have chosen for their first degree. Why can’t he?
- + Show Answer
-
First degree choice is a categorical variable.
2. Amy wants to correlate people’s scores on an anxiety questionnaire with their status – married or not married. Can she?
- + Show Answer
-
Yes, she can use the point biserial correlation coefficient (though better to conduct a difference test e.g., unrelated t).
3. As the number in a sample increases the critical value required for significance with p £ .05 increases or decreases?
- + Show Answer
-
Decreases.
Exercise 19.4
More multiple regression practice
The data set for the multiple regression analysis conducted in the book is called multiple regression data (book).sav and a link to this file is provided below.
Download Exercise 19.4 Data sets
multiple regression data (book).sav
multiple regression data (book).xls
A further exercise in multiple regression can be performed using the file multiple regression ex.sav, which is also provided below. Imagine here that an occupational psychologist has measured ambition, work attitude and absences over the last year and used these to predict productivity over the last three months. If there is good predictive power the set of tests might be used in the selection process for new employees.
Download Exercise 19.4 Data sets
multiple regression exercise.sav
multiple regression exercise.xls
In this exercise please perform the multiple regression analysis in SPSS if you have the programme and then answer the following multiple choice questions:
Interactive Quiz:
Chapter 20 Multi-level analysis – ANOVA for differences between more than two conditions
Exercise 20.1
Calculating one-way unrelated ANOVA
You will need this data sets for this exercise
Download Exercise 20.1 Data sets
1-way unrelated anova ex.sav
1-way unrelated anova ex.xls
These are fictitious data supposedly collected from an experiment in which participants are given (with their permission) either Red Bull (a high caffeine drink), Diet Coke (moderate caffeine) or decaffeinated Coke (no caffeine, i.e., control group). They are then asked to complete a maze task where they have to trace round a maze to find the exit as quickly as possible.
Carry out a one-way ANOVA analysis on the data either in SPSS, using a spreadsheet programme or even by hand and make a full report of results. Include the use of a Tukeyb post-hoc test if possible. If you are calculating by hand you could conduct simple effect t tests between two samples at a time and adjust alpha accordingly.
- + Show Answer
-
F (2, 34) = 6.661, p = .004 (or < .01)
Scores in the Red Bull group are significant higher than scores in the caffeine-free group. This is shown by the Tukeyb test, which says that Red Bull and caffeine-free samples are in different subsets (non-homogenous) or by t tests. The simple t (22) is 3.76 or calculated by the Bonferroni method t (22) is 3.65. Either way this is highly significant (p < .01).
Exercise 20.2
Interpreting SPSS results for a one-way ANOVA
Shown below is the SPSS output after a one-way ANOVA has been performed on data where patients leaving hospital have been treated in three different ways, 1. traditionally (the control group), 2. with extra information (leaflet and video) given as they leave hospital and 3. with this information and a home visit from a health professional. The scores represent an assessment of their quality of recovery after three months. Have a go at answering the multiple-choice questions that appear below.
Test of homogeneity of variances |
|||
Score |
|
|
|
Levene Statistic |
df1 |
df2 |
Sig. |
5.191 |
2 |
36 |
.010 |
ANOVA |
|||||
Score |
|
|
|
|
|
|
Sum of Squares |
df |
Mean Square |
F |
Sig. |
Between Groups |
30.974 |
2 |
15.487 |
5.771 |
.007 |
Within Groups |
96.615 |
36 |
2.684 |
|
|
Total |
127.590 |
38 |
|
|
|
score |
|||
Tukey B |
|
|
|
Type of post-op care |
N |
Subset for alpha = 0.05 |
|
1 |
2 |
||
Trad. care |
13 |
5.3846 |
|
Trad. care + inform. |
13 |
6.7692 |
6.7692 |
trad. care + inform. + visit |
13 |
|
7.5385 |
Means for groups in homogeneous subsets are displayed. |
|||
Interactive Quiz:
Exercise 20.3
The features of post hoc tests
Try the ‘matching’ quiz – match the test with the appropriate description.
Interactive Quiz:
Exercise 20.4
The Jonckheere trend test
On p. 590 of the book there is a description of the Jonckheere trend test, which directs the reader here for the means of calculation. Below is a table of fictitious (and very minimal) data upon which we will conduct the test. This will tell us whether there is a significant trend for scores to increase across the three conditions from left to right. Assume that participants have been given information about a fictitious person including one criterion piece – in condition 1 that the person doesn’t care about global warming, in condition 2 no information about the person’s attitude is given, and in condition 3 the person cares a lot about global warming. The scores in the columns are the participant’s rating of how likely they are to like the person.
|
Experimental conditions |
|
1. Doesn’t care |
Values to right |
2. No information |
Values to right |
3. Cares |
Participant |
|
|
|
|
|
A |
3 |
7 |
2 |
4 |
10 |
B |
5 |
7 |
7 |
3 |
8 |
C |
6 |
7 |
9 |
2 |
7 |
D |
3 |
7 |
8 |
2 |
11 |
Totals: |
28 |
|
11 |
|
|
Procedure |
Calculation |
1. For each score count the number of scores that exceed it to the right. Start at the left-hand column. |
See the table above. Example: The score of 5 for participant B in the ‘Doesn’t care’ column is exceeded by 7, 9 and 8 in the next column and 10, 8, 7 and 11 in the right hand column, making 7 scores in all. |
2. Add the two count columns |
See the table above (‘totals’) |
3. Add the two totals and call this value X |
X = 28 + 11 = 39 |
OK that was the easy part. Now things are rather tricky when we want to check if our value of X is significant. There are tables for this test but they only go up to n = 10 in each condition and you have to have the same number in each condition – a rare circumstance. We need to enter our value of X then into the following equation (take a deep breath):

Sninj means multiply all possible combinations of sample size. If we had sample sizes of 4, 6 and 7 this would mean we found (4x6) + (4x7) + (6x7). In our case here though this is just 4x4 + 4x4 + 4x4 = 48.
S(n2) would be 42 + 62 + 72 but in our case is 3 x 42 = 48
S(n3) would be 43 + 63 + 73 but for us it is 3 x 43 = 132
N is the total sample size, i.e., 3 x 4 = 12
Our z value then is  = 29/Ö[1/18 x 3888 – 144 – 264] = 29/Ö3480/18 = 29/Ö193.33 = 29/13.9 = 2.09
= 29/Ö[1/18 x 3888 – 144 – 264] = 29/Ö3480/18 = 29/Ö193.33 = 29/13.9 = 2.09
A z value of 2.09 cuts off .0183 of the area of the normal distribution at either end (check in Appendix table 2 of the book) and this means that our overall p is 2 x .0183 for a two-tailed test = .0366 so we have a significant trend!
Chapter 21 Multi-factorial ANOVA designs
Exercise 21.1
Calculating two way unrelated ANOVA on a new data set
The data set used to calculate the example of a two-way unrelated ANOVA in this chapter is provided below and is named two way unrelated (book).sav. An Excel file with the same name is also provided.
Download Exercise 21.1 Data sets
Two way unrelated (book).sav
Two way unrelated (book).xls
The data set provided below (two-way unrelated ex) is one of fictitious data from a research project on leadership styles. Each participant has an LPC score, which stands for ‘least preferred co-worker’. People with high scores on this variable are able to get along with and accept relatively uncritically even those workers whom they least prefer to interact with. Such people make good leaders when situations at work are difficult (they are ‘people oriented’). By contrast low LPC people make good task leaders and are particularly effective when working conditions are good but tend to do poorly as leaders when conditions are a little difficult.
The variables in the file are sitfav with levels of highly favourable and moderately favourable (work situation) and lpclead with levels of high and low being the categories of high and low LPC scorers. Hence in these results we would expect to find an interaction between situation favourability and LPC leadership category. High LPC people should do well in moderately favourable conditions whereas low LPC people should do well in highly favourable conditions. Let’s see what the spoof data say. Conduct a two-way unrelated ANOVA analysis, including relevant means and standard deviations, and checking for homogeneity of variance and for effect sizes and power for each test.
Download Exercise 21.1 Data sets
2 way unrelated ex.sav
2 way unrelated ex.xls
The answers I got are revealed when you select the button below.
- + Show Answer
-
The main effect for LPC leadership is not significant (overall one type of leader did no better than the other), F1,20 = 0.381, p = .544. The main effect for situation was also not significant (leadership performances overall were similar for highly and moderately favourable conditions), F1,20 = 1.5, p = .366). However, there was a significant interaction between situation and leadership type. High LPC leaders (M = 5.33, SD = 1.03) scored lower than low LPC leaders (M = 6.5, SD = 1.64) in highly favourable conditions, whereas they scored higher (M = 7.0, SD = 1.41) than low LPC leaders (M = 5.5, SD = 1.05) in moderately favourable conditions, F1,20 = 6.214, p = .022. Levene’s test for homogeneity of variance was not significant so homogeneity was assumed. Partial h2 for the interaction was .237 with power estimated at .660.
Exercise 21.2
Interpreting an SPSS output for a two-way unrelated analysis.
Here is part of the SPSS output data for a quasi-experiment in which participants were grouped according to their attitude towards students. This is the ‘attitude group’ variable in the display below. Each group was exposed to some information about a fictitious person including their position on reintroducing government grants to students. Participants were later asked to rate the person on several characteristics including ‘liking’. It can be assumed for instance that participants who were pro students would show a higher liking for someone who wanted to introduce grants than someone who didn’t. Study the print out and try to answer the questions below.
Levene's test of equality of error variancesa |
|||
Dependent Variable: liking |
|
||
F |
df1 |
df2 |
Sig. |
2.757 |
5 |
41 |
.031 |
|
|||
Tests of between-subjects effects |
|||||
Dependent Variable: liking |
|
|
|
|
|
Source |
Type III sum of squares |
df |
Mean square |
F |
Sig. |
Corrected Model |
114.601a |
5 |
22.920 |
7.947 |
.000 |
Intercept |
1880.558 |
1 |
1880.558 |
652.033 |
.000 |
information |
3.670 |
2 |
1.835 |
.636 |
.534 |
attitudegroup |
15.953 |
1 |
15.953 |
5.531 |
.024 |
information * attitudegroup |
93.557 |
2 |
46.778 |
16.219 |
.000 |
Error |
118.250 |
41 |
2.884 |
|
|
Total |
2135.000 |
47 |
|
|
|
Corrected total |
232.851 |
46 |
|
|
|
a. R Squared = .492 (Adjusted R Squared = .430) |
|
|
|
||
Interactive Quiz:
Chapter 22 ANOVA for repeated measures designs
The data sets used to calculate the repeated measures examples in this chapter are provided below.
Download Exercise 22.1 Data sets
Repeated measures (book).sav
Repeated measures (book).xls
Mixed (book).sav
Mixed (book).xls
2way repeated (book).sav
2way repeated (book) .xls
Exercise 22.1
Calculating a one-way repeated measures ANOVA example
You will need the following data set to complete this exercise:
Download Exercise 22.1 Data sets
repeated measures 1-way ex.sav
repeated measures 1-way ex.xls
The file repeated measures 1-way.sav (SPSS) or repeated measures 1-way.xls (Excel) contains data for a fictitious study in which new employees were assessed for efficiency in their similar jobs after one month, six months and twelve months. Calculate the one-way repeated measures results and compare with the answer given below. The repeated measures variable is contained in the columns entitled efficency1, efficiency6 and efficiency12. In SPSS use the General linear model menu item. Don’t forget to employ Mauchly’s test for sphericity (check the Options button).
- + Show Answer
-
The means (and standard deviations) of the efficiency scores after 1 month, 6 months and 12 months respectively were M = 38.3 (3.91), M = 41.5 (6.51) and M = 46.1 (6.92). The means differed significantly with F2,30 = 8.247, p = .001, effect size (h2)= .355. Mauchly’s test was not significant, p = .49.
Exercise 22.2
Calculating a two-way mixed design ANOVA example
You will need this data set to carry out this exercise:
Download Exercise 22.2 Data sets
repeated measures mixed.sav
repeated measures mixed.xls
In this exercise you can tackle a two-way mixed design where there is one repeated measures factor (efficiency from the last exercise) and one between groups factor. This new factor is one of training.
Imagine the new employees in the last exercise were randomly divided into a group that received no training, one that received training and one that received training and some team building exercises early on in their employment at the company. You need the file repeated measures mixed.sav (SPSS) or repeated measures mixed.xls (Excel).
Conduct the two-way analysis and see if you get the same findings as the report below. Ignore the column headed ‘graduate’ for now. Make sure you inspect the table of means (by asking for Descriptive statistics under the Options button in SPSS). You need the efficiencyaverage variable to calculate overall efficiency means for each training group.
- + Show Answer
-
There was a main effect for efficiency with the means rising from M = 44.8, SD = 5.91 at one month, through M = 45.8, SD = 7.26 at six months to M = 47.8, SD = 6.80 at twelve months. F2.90 = 3.824, p = .025, effect size (partial h2 ) = .078.
There was a main effect for training with means of M = 42.3, SD = 3.41 for the untrained group, M = 47.1, SD = 4.31 for the trained group and M = 49.0, SD = 4.41 for the trained and team building group. F2,45 = 11.564, p < .001, effect size (partial h2 ) = .993.
The interaction was not significant. Sphericity was at an acceptable level (p = .299). Levene’s test for homogeneity of variance was significant for efficiency1 so equality of variances was not assumed for this variable.
If you’re really feeling adventurous you could try the three-way mixed ANOVA that is produced by including the factor of graduate. This tells us whether the participant was a graduate or not. I have only provided brief details of results below but enough to let you see you’ve performed the analysis correctly.
- + Show Answer
-
Main effect efficiency F2,84 = 4.018, p = .022, h2 = .087
Main effect training F2,42 = 15.433, p < .001, h2 = .424
Interaction efficiency x training not significant
Interaction efficiency x graduate not significant
Interaction training x graduate significant F2,42 = 7.708, p = .001, h2 = .268
(graduates better than non-graduates if not trained or trained but with team building too they are worse! – overall).
Three-way interaction efficiency x training x graduate just significant F4,84 = 2.492, p = .049, h2 = .106 (it seems that for team building and training, graduates improved more across the three times than non-graduates and, for training only, non-graduates improved more than graduates).
Exercise 22.3
Calculation of a two-way repeated measures ANOVA
You will need this data set to carry out this exercise:
Download Exercise 22.3 Data sets
2-way repeated-ex.sav
2-way repeated-ex.sav.xls
The data set these files are based on is an experiment where participants undergo the Stroop experience. Stroop was the psychologist responsible for demonstrating the dramatic effect that occurs when people are asked to name the colour of the ink in which words are written – there is a big problem if the word whose colour you are naming is a different colour word (e.g., red written in green – an ‘incongruent’ colour word)! People take much longer to name the ink colour of a set of such words than they do to name the colours of ‘congruent’ words (colour words written in the ink colour of the word they spell).
A further refinement of the experiment, based on a theory of sub-vocal speech when reading, is the prediction that words that sound like colour words (such as ‘shack’ or ‘crown’) should also produce some interference, if incongruent, thus lengthening times to name ink colours. The Stroop factor of this experiment then involves three conditions: naming the ink colour of congruent words; naming the ink colour of incongruent words sounding like colour words; and naming the ink colour of incongruent colour words.
In the imaginary experiment here we have introduced a second factor, which is that people perform the three Stroop tasks both alone and then in front of an audience. The data are presented as a 2 x 3 repeated measures design so there are six columns of raw data, the numbers being number of seconds to read the list of words. Control is naming the ink colour of congruent words, rhyme uses words sounding like incongruent colour words and colour uses incongruent colour words. The end part of each variable refers to the audience conditions, alone if no audience and aud with an audience observing.
Remember that in SPSS you have to name the two repeated measures factors then carefully select columns when asked to define the levels of each variable. If you enter the repeated measures variable names as first ‘stroop’, then ‘audience’ you will be asked to identify variables in the order stroop 1, audience 1, stroop 1, audience 2 and so on, so that’s controlalone, controlaud, rhymealone … and so on. You will need the three extra mean columns when looking at the differences related to the Stroop main effect.
Carry out the two-way analysis, remembering to check Mauchly’s sphericity statistic and to ask for descriptive statistics so you can see the mean of each level of each variable.
- + Show Answer
-
The main effect for Stroop is basically massive (as it nearly always is). The overall means for the three conditions were control M = 44.5 (SD = 14.54), rhyme M = 58.9 (SD = 14.82) and colour M = 97.7 (SD = 20.47). F2,18 = 34.873, p < .001, partial h2 = .795
There was no effect for audience and the interaction stroop x audience was not significant. Sphericity was not a problem.
Exercise 22.4
Questions on SPSS results for a two-way ANOVA
The table below shows part of the SPSS output for a two-way ANOVA calculation. Extroverts and introverts (factor extint) have been asked to perform a task more than once during the day to see whether extroverts improve through the day and introverts worsen.
|
df |
F |
p |
Effect size h2 |
Performance |
2 |
3.795 |
.026 |
.073 |
Performance x extint |
2 |
23.225 |
.000 |
.326 |
Error (performance) |
96 |
|
|
|
Extint |
1 |
.026 |
.872 |
.001 |
Error |
48 |
|
|
|
Interactive Quiz:
Exercise 22.5
The Page trend test
On p. 631 of the book there is a short description of the Page trend test, which is used when you have three or more related sets of data and you want to see whether they follow a trend across conditions. We’ll use the (very minimal) data below as an example. Imagine children have been tested for reading improvement on three successive occasions. We want to see if there is significant improvement.
Reading scores for four children tested three times |
|||||
Score |
Rank |
Score |
Rank |
Score |
Rank |
3 |
2 |
2 |
1 |
10 |
3 |
5 |
1 |
7 |
2 |
8 |
3 |
6 |
1 |
9 |
3 |
7 |
2 |
3 |
1 |
8 |
2 |
11 |
3 |
Totals: |
Ra = 5 |
|
Rb = 8 |
|
Rc = 11 |
Step 1. First we calculate a statistic: ![]() where Rk is the total of each rank column and K is the predicted order of that column. For instance when k is 1 the total is 5 and the predicted order of that column was 1 (we expect children to be lowest here).
where Rk is the total of each rank column and K is the predicted order of that column. For instance when k is 1 the total is 5 and the predicted order of that column was 1 (we expect children to be lowest here).
Hence L = (5 x 1) + (8 x 2) + (11 x 3) = 54
Step 2. Again there are tables for Page but only going up to N = 10. For any value of N we can use the formula:  where n is the sample size and k is the number of conditions, so here we get: (12 x 54) – (36 x 16)/Ö(36 x 8 x 4) = 2.12
where n is the sample size and k is the number of conditions, so here we get: (12 x 54) – (36 x 16)/Ö(36 x 8 x 4) = 2.12
1.96 is the critical value for z at .05, two-tailed so this would be a significant trend.
Chapter 23 Choosing a significance test for your data (and internet resources)
Exercise 23.1
Identifying simple two-condition designs
Some two-condition research designs are outlined below. Your job is to read the information (all of it!) and decide which test it is most appropriate to use. You should read the criteria for selecting tests contained in the first part of Chapter 23 before attempting the exercise. The tests that are possible are listed in the table below. Select parametric tests unless there is information contrary to their use.
Related t |
Unrelated t |
Single sample t |
Mann-Whitney U |
Wilcoxon T |
Pearson correlation |
Spearman correlation |
Chi-square |
Sign test |
1. Children are classified as high or low text-message senders and researchers investigate whether their scores on a reading test differ significantly.
- + Show Answer
- unrelated t
2. The same children as in (1) are recorded as extroverts or introverts with the enquiry being: do extroverts send more texts than introverts?
- + Show Answer
- chi-square
3. Students are tested for self-esteem before and after the exam period to see whether there is a significant change in self-esteem.
- + Show Answer
- related t
4. A researcher believes that stress has an effect on physical health and so measures people’s stress levels with a questionnaire and records the number of times they have visited the doctor with minor ailment over the past two years. She believes stress levels will predict number of visits.
- + Show Answer
- Pearson correlation
5. A class of school pupils is asked to solve a set of simple maths problems, each working on their own and with a prize for the best performance. They are then asked to solve similar problems, but this time they are told they are working as a group and will receive a prize if they beat other groups. The dependent variable is the difference between their two performances and it is found that these scores are very different from a normal distribution in terms of kurtosis.
- + Show Answer
- Wilcoxon
6. The same researcher as in (4) tests the hypothesis that stress affects self-esteem and expects higher stress to produce lowered self-esteem scores. In this project she finds the self-esteem scores are heavily skewed and cannot remove this with a transformation.
- + Show Answer
- Spearman’s correlation
7. A sample of people is found who have just completed their second degree. A researcher is interested in whether their second degree category is better than their first degree category. Since degree grades are categorical the only record is whether the second degree was better or worse than the first.
- + Show Answer
- Sign test
8. Participants are divided into two groups. One group is asked to doodle (by filling in letters) while listening to a guest list of names invited to a party. A control group does the same task without doodling. It is predicted that the doodle group will perform better when asked to recall as many names as possible. The variances of the two groups are very different and there are quite different numbers of participants in each group.
- + Show Answer
- Mann-Whitney U
Exercise 23.2
Identifying ANOVA designs
From the following brief descriptions of research designs try to identify the ANOVA type with factors and levels. For instance, an answer might be one-way, unrelated or 2 x 3 x 2 mixed.
One-way |
|
Unrelated |
2 x 3 |
|
Repeated measures |
3 x 3 |
|
Mixed |
2 x 3 x 2 |
|
|
3 x 4 |
|
|
1. Participants are asked to rate a fictitious person having been told they are either pro-hanging, anti-hanging or neutral.
- + Show Answer
- One-way unrelated
2. Participants are presented with both positive and negative traits for later recall and are induced into either a depressed, neutral or elated mood.
- + Show Answer
- 2 x 3 mixed
3. All participants are asked to name colours of colour patches, non-colour words and colour words.
- + Show Answer
- One-way repeated measures
4. Male and female clients experience either psychoanalysis, behaviour modification or humanistic therapy and effects are assessed.
- + Show Answer
- 2 x 3 unrelated
5. Participants are given either coffee, alcohol or a placebo and are all asked to perform a visual monitoring task under conditions of loud, moderate, intermittent and no noise.
- + Show Answer
- 3 x 4 mixed
6. Older or younger participants are asked to use one of three different memorising methods.
- + Show Answer
- 2 x 3 unrelated
7. Extroverts and introverts are tested at weekly intervals and are asked to perform an energetic and then a dull task after being given first a stimulant, then a tranquiliser and then a placebo.
- + Show Answer
- 2 x 2 x 3 mixed
8. Participants perform tasks in front of an audience and when alone. They are first asked to sort cards into three piles, then four piles and finally five piles.
- + Show Answer
- 2 x 3 repeated measures
Chapter 24 Planning your practical and writing up your report
Exercise 24.1
Identifying problematic report statements
In the extracts from students’ psychology practical reports below try to describe what is dubious about the statement before checking the answers.
1. An experiment to see whether giving people coffee, decaffeinated coffee or water will have an effect on their memory of 20 items in a list.
- + Show Answer
- Far too long-winded and could be stripped nicely down to: ‘The experimental effect of caffeine on recall memory’.
2. The design was an experiment using different types of drink …
- + Show Answer
- What kind of experiment? It’s true that we might be told later what kinds of drink were used but why not just explicitly state the levels of the independent variable straight away?
3. 20 students were selected at random and asked …
- + Show Answer
- Hardly likely that they were selected truly at random. Probably ‘haphazardly’.
4. Materials used were a distraction task, a questionnaire, mirrors …
- + Show Answer
- Never list materials, use normal prose description.
5. The results were tested with a t test …
- + Show Answer
- Which results? In the simplest studies there are always several ways in which the data could be tested. We could, for instance test the difference between standard deviations rather than means. Usually though the reader needs to know explicitly which means were tested – there are usually more than just two, and anyway ‘results’ is just vague.
6. Miller (2008) stated that “There is no such thing as a loving smack. The term is an oxymoron. No child feels love as they are being beaten or slapped.”
- + Show Answer
- No page number for the quotation.
7. The result proved that …
- + Show Answer
- We never use ‘prove’ in psychology, or in most practical sciences for that matter. Findings usually support a hypothesis or theory, or they challenge it.